
개요
이전 글에서 Prometheus + Grafana 모니터링 환경을 구축했습니다. 대시보드로 메트릭을 눈으로 확인하는 것만으로는 부족합니다. 서버에 문제가 생겼을 때 담당자가 직접 대시보드를 보고 있지 않으면 이상 징후를 놓칠 수 있기 때문입니다.
이번 글에서는 GC 이후에도 힙 메모리가 80%를 초과하면 Slack으로 알림을 발송하는 Grafana Alert를 설정합니다.
단순히 “지금 힙이 80% 이상”이면 알림을 보내는 방식은 GC가 일어나기 직전에도 알림이 발생하는 노이즈가 많습니다. 핵심은 GC를 해도 회수되지 않는 메모리가 80%를 넘는지 여부이며, 이를 감지하려면 jvm_gc_live_data_size_bytes 메트릭을 사용해야 합니다.
jvm_gc_live_data_size_bytes는 Micrometer가 Major GC(Full GC) 완료 직후 Old Generation에 살아남은 바이트 수를 기록하는 메트릭입니다. 이 값이 높다는 것은 GC를 수행했음에도 객체가 회수되지 않았음을 의미합니다.
GC 이후에도 힙 메모리 점유율이 80%를 넘는다는 것은 두 가지 중 하나를 의미합니다.
- 메모리 누수(Memory Leak): 객체가 GC의 회수 대상이 되지 않고 계속 쌓이는 상태
- 힙 사이즈 부족: 서비스 부하에 비해 현재 할당된 힙 크기가 절대적으로 부족한 상태
두 경우 모두 방치하면 OutOfMemoryError로 이어져 서비스 장애가 발생합니다. 알림을 통해 사전에 감지하고 대응해야 합니다.
전체 흐름
1
2
3
4
5
6
7
Prometheus (메트릭 수집)
↓ 15초마다 scrape
Grafana Alert Rule (PromQL 평가)
↓ 5분간 80% 초과 지속 시
Contact Point (Slack Webhook)
↓
Slack 채널에 알림 메시지 발송
Grafana Alert는 Alert Rule → Notification Policy → Contact Point 세 가지 구성요소로 동작합니다.
| 구성요소 | 역할 |
|---|---|
| Alert Rule | 어떤 조건일 때 알림을 발생시킬지 정의 |
| Contact Point | 알림을 어디로 보낼지 정의 (Slack, Email 등) |
| Notification Policy | Alert Rule과 Contact Point를 연결하는 라우팅 규칙 |
Step 1. Slack Incoming Webhook 설정
알림을 받을 Slack 채널에 Webhook URL을 먼저 발급해야 합니다.
- Slack API 페이지에서 Create New App 클릭
- From scratch 선택 → App Name 입력 → Workspace 선택
- 왼쪽 메뉴에서 Incoming Webhooks 클릭 → Activate Incoming Webhooks 토글 ON
- 하단의 Add New Webhook to Workspace 클릭 → 채널 선택 → Allow
- 생성된 Webhook URL 복사 (형식:
https://hooks.slack.com/services/T.../B.../...)
Step 2. Grafana Contact Point 등록
Grafana에서 Slack Webhook을 Contact Point로 등록합니다.
- Grafana 왼쪽 사이드바에서 종 모양 아이콘(Alerting) 클릭
- Contact points 메뉴 선택
- + Add contact point 클릭
- 아래와 같이 입력합니다.
| 항목 | 값 | |—|—| | Name | slack-alert (식별용 이름) | | Integration | Slack 선택 | | Webhook URL | Step 1에서 복사한 URL 붙여넣기 |
- 하단의 Test 버튼을 클릭해 Slack 채널로 테스트 메시지가 오는지 확인합니다.
- Save contact point 클릭
Test 버튼은 실제 알림이 발송되는지 사전 검증할 수 있는 가장 빠른 방법입니다. Alert Rule을 만들기 전에 반드시 테스트하세요.
Step 3. Alert Rule 생성
3-1. 알림 규칙 생성 화면 진입
- Grafana 왼쪽 사이드바에서 Alerting > Alert rules 선택
- 오른쪽 상단의 + New alert rule 버튼 클릭
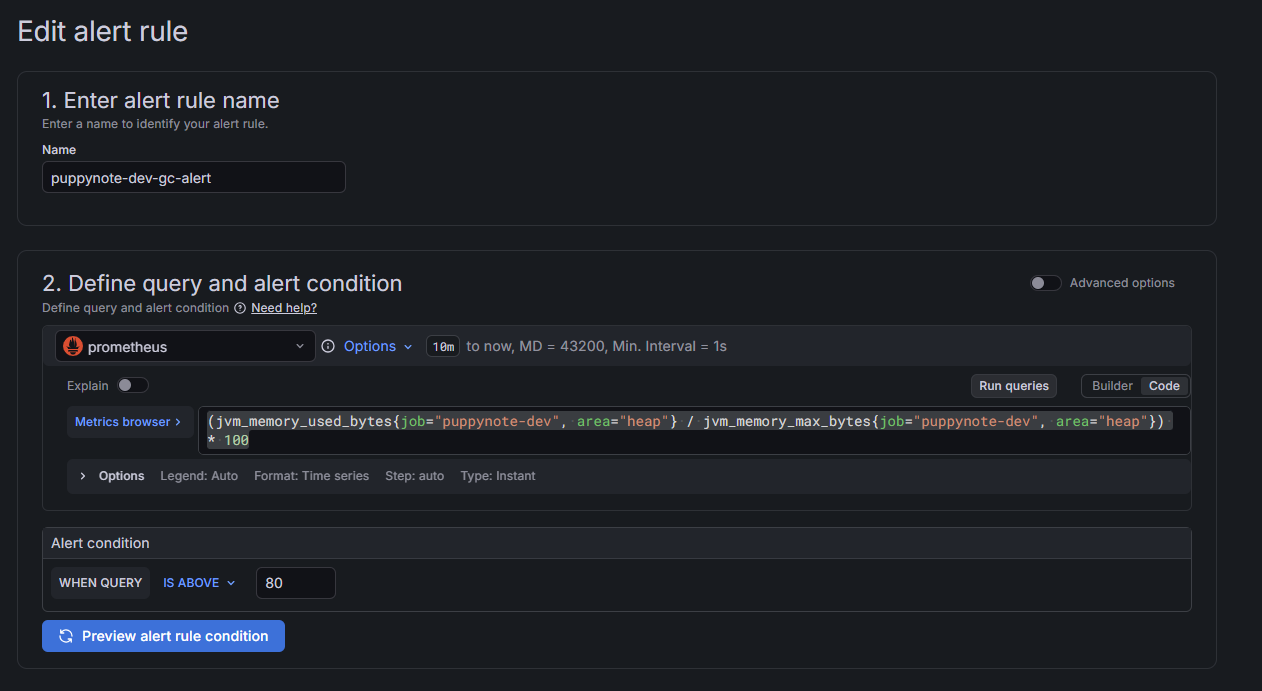
3-2. 쿼리 설정 (Define query and condition)
이 단계에서 “어떤 메트릭이 어떤 값을 넘으면 알림을 줄 것인가”를 정의합니다.
- Rule name:
원하는 룰 네임 - Query (A) 섹션에서 데이터소스를 Prometheus로 선택하고 아래 PromQL을 입력합니다.
(jvm_gc_live_data_size_bytes{job="puppynote-dev"} / jvm_gc_max_data_size_bytes{job="puppynote-dev"}) * 100
puppynote-dev는 Prometheus scrape 시 설정한 job 레이블 값입니다. 실제 환경에 맞게 수정해야 합니다.
| 메트릭 | 의미 |
|---|---|
jvm_gc_live_data_size_bytes | 가장 최근 Major GC 완료 직후 Old Gen에 살아남은 바이트 수 |
jvm_gc_max_data_size_bytes | Old Gen 최대 크기 |
이 쿼리는 GC 후에도 회수되지 않고 살아남은 메모리가 Old Gen 최대 크기 대비 몇 %인지를 계산합니다. jvm_memory_used_bytes와 달리 GC 이전 순간의 값은 반영되지 않아 노이즈가 적습니다.
- Expression (B) 섹션에서 임계치 조건을 설정합니다.
- Operation:
Last(마지막 값 기준으로 평가) - Condition:
Is above - Value:
80
- Operation:
Expression은 Query 결과에 대한 추가 연산입니다.
Reduce로 시계열을 단일 값으로 줄인 뒤,Threshold로 임계치를 비교하는 두 단계로 구성할 수도 있습니다.
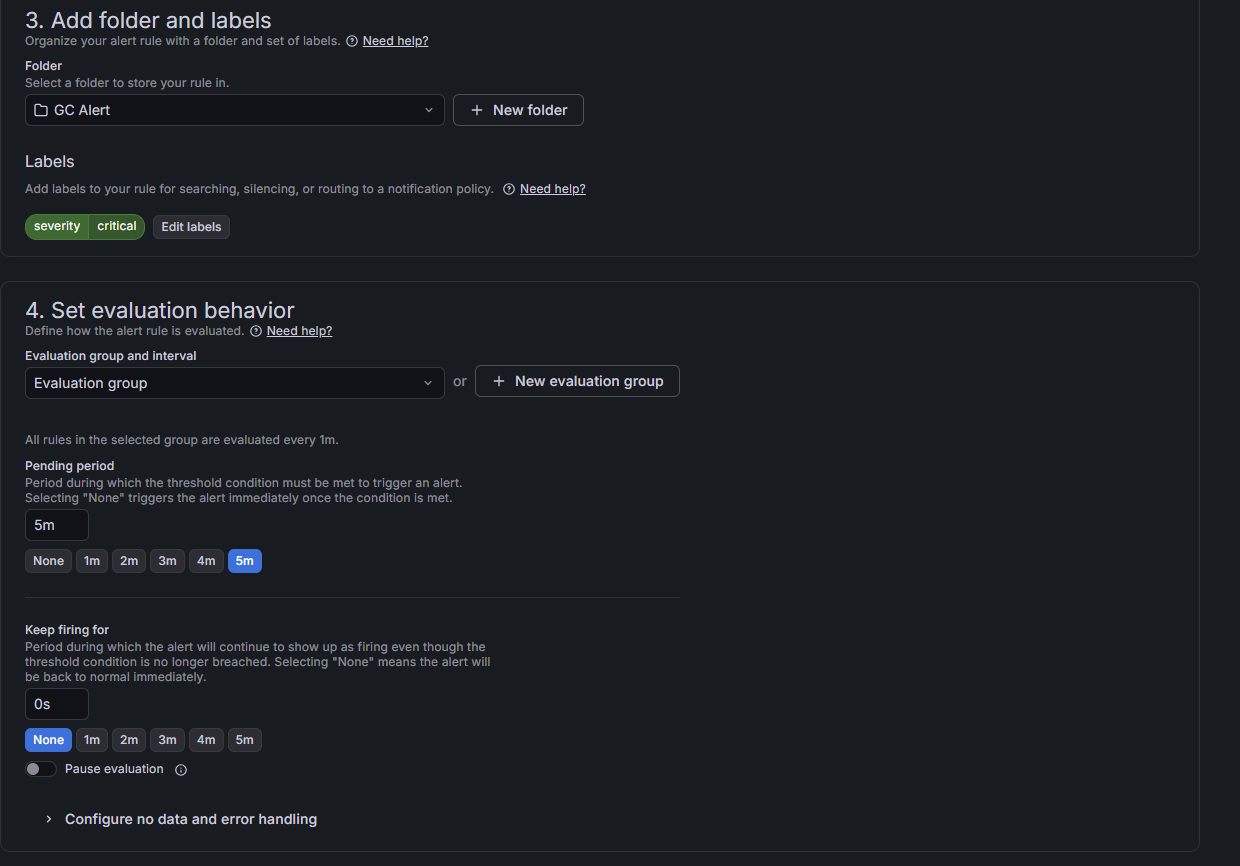
3-3. 평가 주기 설정 (Set evaluation behavior)
Major GC 이후 live data 비율이 일시적으로 높게 찍힌 것인지, 아니면 지속적으로 80%를 넘고 있는지 구분하는 단계입니다.
| 항목 | 값 | 설명 |
|---|---|---|
| Evaluation group | jvm-alerts (신규 생성) | Alert Rule을 묶는 그룹 단위 |
| Evaluation interval | 1m | 1분마다 조건 평가 |
| Pending period | 5m | 5분간 계속 조건을 만족할 때만 Firing |
Pending period가 중요합니다. GC는 수시로 발생하므로 순간적인 피크에 알림이 울리면 노이즈가 됩니다. 5m으로 설정하면 5분 내내 80%를 초과할 때만 실제 알림이 발송됩니다.
알림 상태 전이는 아래와 같습니다.
1
2
Normal → Pending (조건 충족, 5분 카운트) → Firing (알림 발송)
Firing → Normal (조건 해소 시 자동 복구 알림)
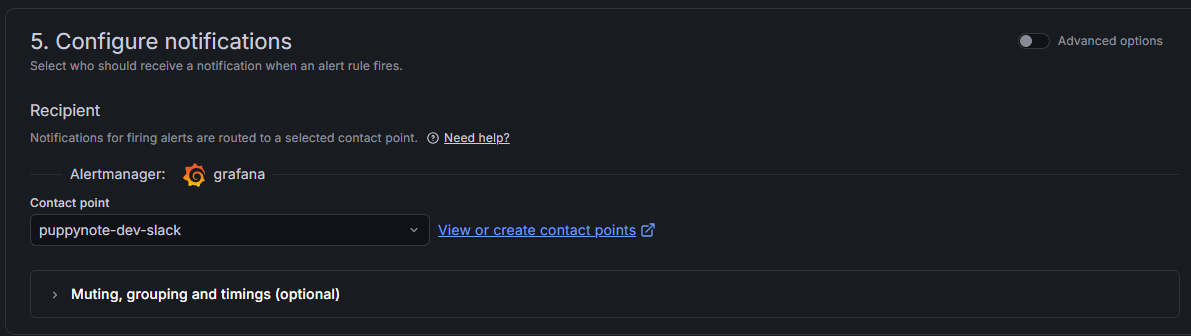
3-4. 알림 발송 채널 연결 (Notifications)
- Contact point 드롭다운에서 Step 2에서 만든
slack-alert선택 - 오른쪽 상단의 Save rule and exit 클릭
최종 확인
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
@RestController
@Profile("dev")
@RequestMapping("/api/v1/test")
public class MemoryTestController {
private final List<byte[]> memoryHolder = new ArrayList<>();
// 메모리를 채워 GC 유발 후에도 80% 이상 유지
@PostMapping("/memory/pressure")
public String fillMemory() {
// 10MB 씩 20번 = 200MB 할당
for (int i = 0; i < 20; i++) {
memoryHolder.add(new byte[10 * 1024 * 1024]);
}
Runtime runtime = Runtime.getRuntime();
long used = runtime.totalMemory() - runtime.freeMemory();
long max = runtime.maxMemory();
long usagePercent = used * 100 / max;
return String.format("메모리 할당 완료 - 사용률: %d%% (%dMB / %dMB)",
usagePercent, used / 1024 / 1024, max / 1024 / 1024);
}
// GC 강제 실행 (메모리는 유지)
@PostMapping("/memory/gc")
public String forceGc() {
System.gc();
Runtime runtime = Runtime.getRuntime();
long used = runtime.totalMemory() - runtime.freeMemory();
long max = runtime.maxMemory();
long usagePercent = used * 100 / max;
return String.format("GC 실행 완료 - 사용률: %d%% (%dMB / %dMB)",
usagePercent, used / 1024 / 1024, max / 1024 / 1024);
}
// 메모리 해제
@DeleteMapping("/memory/release")
public String releaseMemory() {
memoryHolder.clear();
System.gc();
Runtime runtime = Runtime.getRuntime();
long used = runtime.totalMemory() - runtime.freeMemory();
long max = runtime.maxMemory();
long usagePercent = used * 100 / max;
return String.format("메모리 해제 완료 - 사용률: %d%% (%dMB / %dMB)",
usagePercent, used / 1024 / 1024, max / 1024 / 1024);
}
}
경고메시지 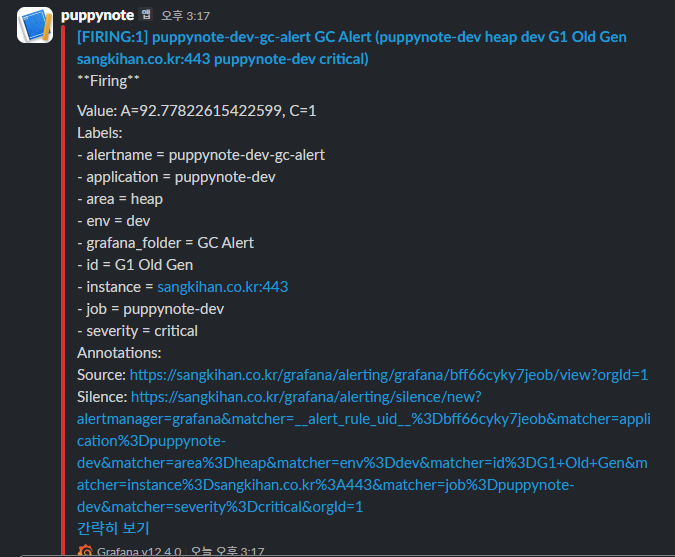 복구메시지
복구메시지 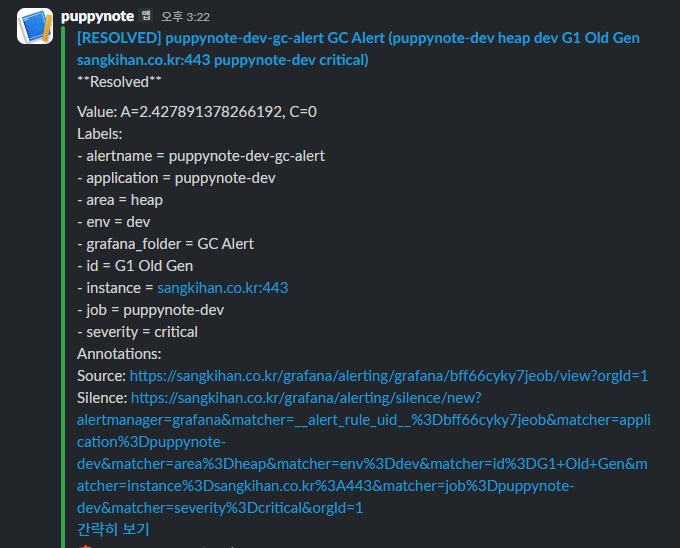
Grafana Alert가 정상적으로 동작하면 장애 상황에서 대시보드를 직접 보지 않아도 Slack 알림을 통해 즉시 대응할 수 있습니다.